
Sometimes on DQYDJ we like to reveal a little bit of the process behind the data. In that past, that has meant articles on how we ingest fixed width data with R and how we model the cost of a Negative Income Tax in America, amongst many other fine examples.
Today I'll be sharing some explorations with Big Data. For a change of pace I'll be doing it with the world's most famous Little Computer - the Raspberry Pi. If that's not your thing, we'll see you in the next piece (probably with some already finished data). For the rest of you, read on... today we're going to build a Raspberry Pi Hadoop Cluster!
Why Build a Raspberry Pi Hadoop Cluster?

We do a lot of work with data here on DQYDJ, but nothing we have done qualifies as Big Data.
Like so many controversial topics, the difference between "Big" Data and lower-case data might be best explained with a joke:
"If it fits in RAM, it's not Big Data." - Unknown (If you know, pass it along!)
It seems like there are two solutions to the problem here:
- We can find a dataset big enough to overwhelm any actual physical or virtual RAM on our home computers.
- Or, we can buy some computers where the data we have now would overwhelm the machine without special treatment.
Enter the Raspberry Pi 2 Model B!
These impressive little works of art and engineering have 1 GB of RAM and your choice of MicroSD card for a hard drive. Furthermore, you can get them for under $50 each, so you can build out a Hadoop cluster for under $250.
There might be no cheaper ticket into the Big Data world!
Building The Raspberry Pi Hadoop Cluster
Now I'll link you to what I used to build the cluster itself. Note that if you do buy on Amazon using these links you'll be supporting the site. (Thank you for the support!)

4 Layer Acrylic Case/Stand6 Post USB Charger (I picked the White RAVPower 50W 10A 6-Port USB Charger) 5 Port Ethernet Switch (Fast is fine, the ethernet ports on the Pi are only 100 Mbit) MicroSD Cards (This 5 pack of 32 GB cards was perfectly fine) Short MicroUSB Cables (to power the Pis) Short Ethernet Patch Cables Two sided foam tape (I had some 3M brand, it worked wonderfully)
Now Bake the Pis!
- First, mount the three Raspberry Pis, one each to an acrylic panel (see the below image).
- Next, mount the ethernet switch to a fourth acrylic panel with 2 sided foam tape.
- Mount the USB charger on the acrylic panel which will become the 'top' (again with 2 sided foam tape)
- Follow the instructions for the acrylic case and build the levels - I chose to put the Pis below the switch and charger (see the two completed build shots).
Figure out a way to get the wires where you need them - if you bought the same USB cables and Ethernet cables as me, I was able to wrap them around the mounting posts between levels.
Leave the Pis unplugged for now - you will burn the Raspbian OS on the MicroSDs before continuing.

Burn Raspbian to the MicroSDs!
Put Raspbian on 3 MicroSDs - follow the instructions on the Raspberry Pi Raspbian page. I use my Windows 7 PC for this, and Win32DiskImager.
Pop one of the cards into whatever Pi you want to be the master node, then start it up by plugging in USB!
Setup the Master
There is no need for me to repeat an excellent guide here - you should follow the instructions in Because We Can Geek's guide and install Hadoop 2.7.1. (Ed: As pointed out in the comments, Because You Can Geek might be down - try that first, otherwise here is an archived link.).
There were a few caveats with my setup - I'll walk you through what I ended up using to get a working setup. Note that I am using the IP addresses 192.168.1.50 - 192.168.1.52, with the two slaves on .51 and .52 and the master on .50. Your network will vary, you will have to look around or discuss this step in the comments if you need help setting up static addresses on your network.
Once you are done with the guide, you should enable a swapfile. Spark on YARN will be cutting it very close on RAM, so faking it with a swapfile is what you'll need as you approach memory limits.
(If you haven't done this before, this tutorial will get you there. Keep swappiness at a low level - MicroSD cards don't handle it well).
Now I'm ready to share some subtle differences between my setup and Because We Can Geek's.
For starters, make sure you pick uniform names for all of your Pi nodes - in /etc/hostname, I used 'RaspberryPiHadoopMaster' for the master, and 'RaspberryPiHadoopSlave#' for the slaves.
Here is my /etc/hosts on the Master:
You will also need to edit a few configuration files in order to get Hadoop, YARN, and Spark playing nicely. (You may as well make these edits now.)
Here is hdfs-site.xml:
yarn-site.xml (Note the changes in memory!):
slaves:
core-site.xml:
Setup the 2 Slaves
Again, just follow the instructions on Because We Can Geek. You will need to make minor edits to the files above - note that the master doesn't change in yarn-site.xml, and you do not need to have a slaves file on the slaves themselves.
Test YARN on the Raspberry Pi Hadoop Cluster
If everything is working, on the master you should be able to do a:
> start-dfs.sh
> start-yarn.sh
And see everything come up! Do this from the Hadoop user, which will be 'hduser' if you obey the tutorials.
Next, run 'hdfs dfsadmin -report' to see if all three datanodes have come up. Verify you have the bolded line in your report, 'Live datanodes (3)':
Configured Capacity: 93855559680 (87.41 GB)

Present Capacity: 65321992192 (60.84 GB)
DFS Remaining: 62206627840 (57.93 GB)
DFS Used: 3115364352 (2.90 GB)
DFS Used%: 4.77%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
-------------------------------------------------
Live datanodes (3):
Name: 192.168.1.51:50010 (RaspberryPiHadoopSlave1)
Hostname: RaspberryPiHadoopSlave1
Decommission Status : Normal
...
...
...
You may now run through some 'Hello, World!' type exercises, or feel free to move to the next step!
Install Spark on YARN on Pi
YARN stands for Yet Another Resource Negotiator, and is included in the base Hadoop install as an easy to use resource manager.
Apache Spark is another package in the Hadoop ecosystem - it's an execution engine, much like the (in)famous and bundled MapReduce. At a general level, Spark benefits from in-memory storage over the disk-based storage of MapReduce. Some workloads will run at 10-100x the speed of a comparable MapReduce workload - after you've got your cluster built, read a bit on the difference between Spark and MapReduce.
On a personal level, I was particularly impressed with the Spark offering because of the easy integration of two languages used quite often by Data Engineers and Scientists - Python and R.
Installation of Apache Spark is very easy - in your home directory, 'wget <path to a Apache Spark built for Hadoop 2.7>' (from this page). Then, 'tar -xzf <that tgz file>'. Finally, copy the resulting directory to /opt and clean up any of the files you downloaded - that's all there is to it!
I also have a two line 'spark-env.sh' file, which is inside the 'conf' directory of Spark:
SPARK_MASTER_IP=192.168.1.50
SPARK_WORKER_MEMORY=512m
(I'm not even sure this is necessary, since we will be running on YARN)
"Hello, World!" Finding an Interesting Data-set for Apache Spark
The canonical 'Hello, World!' in the Hadoop world is to do some sort of word counting.
I decided that I wanted my introduction to do something introspective... why not count my most commonly used words on this site? Perhaps some big data about myself would be useful...maybe?
It's a simple two step process to dump and sanitize your blog data, if you're running on WordPress like we are.
- I used 'Export to Text' to dump all of my content into a text file.
- I wrote some quick Python to strip all the HTML using the library bleach:
Now you'll have a smaller file suitable for copying to HDFS on your Pi cluster!
If you didn't do this work on the master Pi, find a way to transfer it over (scp, rsync, etc.), and copy it to HDFS with a command like this:
hdfs dfs -copyFromLocal dqydj_stripped.txt /dqydj_stripped.txt
You're now ready for the final step - writing some code for Apache Spark!
Lighting Apache Spark
Cloudera had an excellent program to use as a base for our super-wordcount program, which you can find here. We're going to modify it for our introspective Word Counting program.
Install the package 'stop-words' for Python on your master Pi. Although interesting (I've used the word 'the' on DQYDJ 23,295 times!), you probably don't want to see your stop words dominating the top of your data. Additionally, replace any references to my dqydj files in the following code with the path to your own special dataset:
Save wordCount.py and make sure all of your paths are correct.
Now you're ready for the incantation that got Spark running on YARN for me, and (drumroll, please) revealed which words I use the most on DQYDJ:
/opt/spark-2.0.0-bin-hadoop2.7/bin/spark-submit --master yarn --executor-memory 512m --name wordcount --executor-cores 8 wordCount.py /dqydj_stripped.txt
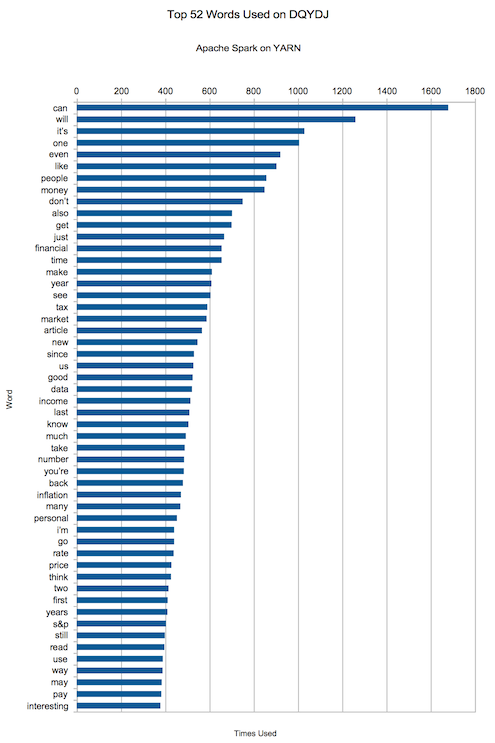
The Conclusion: Which Words Do I Use the Most on DQYDJ?
The top ten "non-stop words" on DQYDJ? "can, will, it's, one, even, like, people, money, don't, also".
Hey, not bad - money snuck into the top ten. That seems like a good thing to talk about on a website dedicated to finance, investing and economics - right?
Here's the rest of the top 50 most frequently used words by yours truly. Please use them to draw wild conclusions about the quality of the rest of my posts!
I hope you enjoyed this introduction to Hadoop, YARN, and Apache Spark - you're now set to go off and write other applications on top of Spark.
Your next step is to start to read through the documentation of Pyspark (and the libraries for other languages too, if you're so inclined) to learn some of the functionality available to you. Depending on your interests and how your data is actually stored, you'll have a number of paths to explore further - there are packages for streaming data, SQL, and even machine learning!
What do you think? Are you going to build a Raspberry Pi Hadoop Cluster? Want to rent some time on mine? What's the most surprising word you see up there, and why is it 'S&P'?
